I heard a lot about the book “The FIVE DYSFUNCTIONS of a TEAM” by Patrick Lencioni previously and found it on a list named “The Best Company Culture Books To Read“. It felt like I should give it a try.
Book structure
The book’ content wraps around a really great story around executives of a virtual tech company in the Silicon Valey finding their way from being a wild group of individuals towards a real team. There is Kathryn, a really experienced CEO coming from a totally different industry background. Jeff, the former CEO and one of the founders – now looking after business development. The CMO, Mikey, a big-shot contributor with an incredible backlog of successes in the broader tech industry. The CTO, Martin, very strong opinionated person with a clear tech-nerdy attitude and among the founding team. The CSO, JR with also a quite huge list of successes on sales side – always increased revenues quarter over quarter. The Chief of Customer Support, Carlos – one of the buddies of Mikey and a quite silent person. The CFO, Jan, who is very carefully keeping the money of the company together and the COO, Nick, who was brought to the company to fix operations.
The story is a great read and I could sympathize with various characters right from the beginning. I could also see some parallels to some of my colleagues in leadership positions. So, the fictional story is not that fictional after all. The fictive CEO Kathryn is one of the CEO’s you would want to work for – or even better – being such a role-model as a C-Level yourself.
My learnings
Patrick wraps his learnings from working with teams in this story and gives some advice at the end of the book on how to overcome the described dysfunctions. Patrick talks on his website more about the details of the model: Teamwork: The Five Dysfunctions of a Team.
Nevertheless, I’ll sum up what I learned in the next brief paragraphs.
The book is a great read. I found myself in various situations and couldn’t agree more with Patrick on his observations on leadership teams. I had the pleasure to work with outstanding CEO’s in the past, myself. One of them being Martina Bruder, the CEO at my times at FriendScout24 and the other being Florian Geuppert the CEO at gutefrage.net. It has been great to be part of the team since these teams were build around trust. I, however, worked with other leadership teams as well and know the situations described by Patrick first hand.
So, go on, build you own opinion and enjoy the story Patrick Lencioni created!
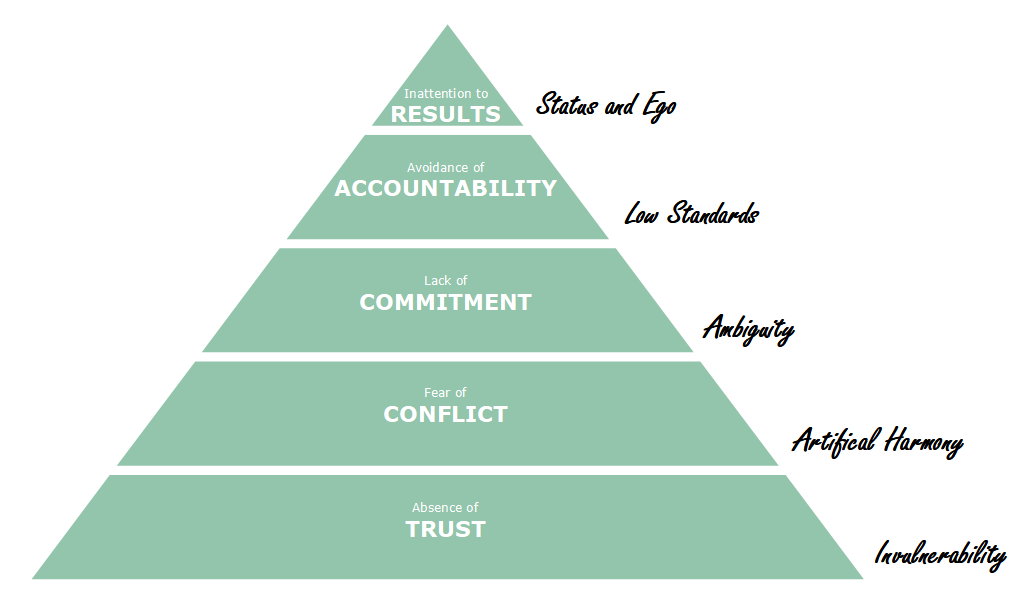
Dysfunction #1 – Absence of Trust
Absence of Trust among team members is primarily due to their reluctance to show vulnerability in front of the group. It is impossible to establish a basis for trust when team members are not genuinely honest with one another about their mistakes and weaknesses.
Dysfunction #2 – Fear of Conflict
Being unable to establish trust is problematic because it supports Fear of Conflict. Teams lacking in trust are unable to have frank and impassioned discussions about their positions. Instead, they use secret conversations and cautious remarks to create an environment of artificial harmony.
Dysfunction #3 – Lack of Commitment
The absence of healthy conflict is a real issue because it makes Lack of Commitment more likely. Team members rarely, if ever, buy in and commit to decisions without first raising their viewpoints during intense and open debate, even though they may pretend to agree during meetings.Returning back to their teams these team members are more likely to defend their own opinions and increase ambiguity in leadership.
Dysfunction #4 – Avoidance of Accountability
Team members try to avoid accountability as a result of this lack of commitment and buy-in. Even the most motivated and dedicated people actually hesitate to confront their teammates about actions and behaviors that seem to be unfavorable to the success of their own team unless they have agreed to a clear plan of action.
Dysfunction #5 – Inattention to Results
Inattention to Results can develop in an environment where people fail to hold one another accountable. It happens when team members prioritize their own interests over the group’s objectives, such as ego, professional advancement, or recognition, or even the demands of their own divisions.
Leaders, what can you expect from your peers? What do they expect from you?
Issue 3 of the three-part series focuses on my expectations of leaders in terms of Your Role & Yourself.
On my journey to my personal core values, I have addressed a number of topics. Among others, I asked myself: “What do I expect from colleagues in leadership positions?” and also “What is my role as a leader?” These questions are anything but easy to answer. My expectations in this series of three posts reflect the bare “minimum” that I expect from a reflective leader. Beyond this minimum, only the sky is the limit.
Delegation is a core principle of leadership. To achieve a vision as a team, a leader must ignite enthusiasm for this very vision and create a culture of willingness among people to achieve the vision, to implement it. People are the heart of every company. They are knowledge carriers, experts and carry the organisation on their shoulders. The willingness to implement a tactic and a strategy to achieve a mission and ultimately a vision depends on the ability of individuals to contribute to the achievement of the vision. Huge companies, such as Google or Amazon, have built a strong vision and an organisation that enables people to move towards that vision. The individual contribution to achieving the vision is marginal. But the reward for the individual is a high salary and working for a great brand. Smaller organisations can attract great talent only with much lower salaries if they promise them that they will have a big impact on the process to achieve the vision. This motivates employees to go the extra mile and exceed expectations.
All this is ONLY possible if top management is willing to delegate responsibility and ownership to their subordinates*)**). Delegation must be done in a transparent way with clear boundaries – both in terms of expectations and the freedom of subordinates to decide to the best of their ability. Delegation requires leaders who are willing to relinquish control, lower their expectations of results, and change the standard for evaluating results from their personal standard. Other people will perform, in different ways, with unexpected results, with aspects not previously considered. The unwillingness to delegate is a major barrier to organisational growth and development. Great ideas will remain ideas because they are not operationalised. They will not be executed. So, one of my expectations on leaders is to delegate work to their teams.
You to communicate – acceptance of responsibility
The actions of leaders are always under observation. The organization misses no step, no word, no communication. Not communicating is not possible, not speaking out is a message to the organisation. Therefore, leaders in particular must take responsibility for their own actions at all times and also stand up for them accordingly. There is no concept of “non-communication”.
Watch yourself – recognizing limits
Top management – also consists of: People. People also reach their limits at the leadership level – and grow. Especially in growth phases, it is important not to forget what tasks every executive has. When someone reaches limits, it is crucial for the senior leader – but moreover – for the entire organisation that these limits are recognised and actively shaped. Actively asking for help is not a sign of weakness, but a sign of strength. Doing so, multiple minds can tackle the challenge at hand. On of my expectations on leaders is to ask for support, reach out for help – if needed.
Next level leadership – lead the leaders
Managing regular employees is already a very complex process. Providing perspectives, communicating purpose, defining goals, tracking progress, instilling confidence, tracking personal development and helping to grow into the role.
Leading employees who are themselves in the role of leaders is even more complex. Now the staff member wants to be led themselves, but needs freedom, information (e.g. budget) and clearer boundaries within which their own staff can act. This is a task that senior executives must master – especially in a fast-growing organisation.
Leaders, what can you expect from your peers? What do they expect from you?
Issue 2 of the three-part series focuses on my expectations of leaders in terms of Company Culture.
On my journey to my personal core values, I have addressed a number of topics. Among others, I asked myself: “What do I expect from colleagues in leadership positions?” and also “What is my role as a leader?” These questions are anything but easy to answer. My expectations in this series of three posts reflect the bare “minimum” that I expect from a reflective leader. Beyond this minimum, only the sky is the limit.
Top senior leadership responsibility – culture building
Culture is so intangible, so abstract. It’s so difficult to actually create it and to steer it purposefully in any direction. It is so indirect, there are so many levers to turn. That is why I have observed that many leaders do not consciously invest time in working on culture. They don’t have a clear goal in mind and don’t know what kind of culture to create.
Nevertheless, Peter Drucker nailed it with his famous statement:
Means? It means that the culture of a company always determines its success, regardless of how effective your strategy is. However, a strategy is easier to define, easier to extract. It is a much easier task than working on culture. Nevertheless, corporate culture is largely determined by the leadership team. Take your responsibility and work on the culture! Don’t leave culture to chance, but try to influence the outcome. One of my expectations on leaders is to work hard to create an excellent company culture!
Foster fast learning – mistake culture
Mistakes are the fastest way to gain experiences – to learn*). Mistakes are okay. In the right culture, mistakes are celebrated and no one is afraid to make them. If mistakes don’t have negative consequences, people will stand by their mistakes. A cornerstone for invention! People want to think about problems and find solutions. Allow this to happen.
I Have Not Failed. I’ve Just Found 10,000 Ways That Won’t Work. *)
Thomas edison
Admitting mistakes is often interpreted as a sign of weakness in some societies. That is why mistakes are all too readily covered up, passed on. In my eyes, admitting and standing by mistakes is a sign of strength, of self-confidence. A strong leadership team fosters a culture where mistakes are allowed and encouraged so the whole organization can learn as quickly as possible. Naturally so, one of my expectations on leaders is to create a mistake culture.
Leaders, what can you expect from your peers? What do they expect from you?
Issue 1 of the three-part series focuses on my expectations of leaders in terms of People, Respect and Appreciation.
On my journey to my personal core values, I have addressed a number of topics. Among others, I asked myself: “What do I expect from colleagues in leadership positions?” and also “What is my role as a leader?” These questions are anything but easy to answer. My expectations in this series of three posts reflect the bare “minimum” that I expect from a reflective leader. Beyond this minimum, only the sky is the limit.
Punctuality Top-level management is punctual to agreed appointments. Nothing to add. Time of employees is as valuable as time of senior management.
Appreciation and Respect are due to people, but also to work results. For me especially appropriate language expresses appreciation and respect for people – employees, colleagues, customers, suppliers, janitors.
Verbally degrading people and results in public (e.g. ‘… we need to get this sh*t out …’ or ‘… this stupid idiot of a janitor …’) raises questions with people – ‘Why am I working on this sh*t?’, ‘How do they name me when I’m not present?’. This doesn’t create a culture of trust and willingness to out-perform.
I expect any level of management to show appreciation for the effort that is being put forth within the organization. Teams that go above and beyond and deliver need appreciation. This can come in the form of praise, recognition, and especially appropriate language.
Employees are adults management members are not mommy and daddy. Employees are grown-up, intelligent people who enjoy coming to work to contribute. If this were not the case, we should ask ourselves why the organization employs them. One of my expectations on leaders is to treat employees as grown-ups!
Attitude towards people – empathy
Empathy (= the capacity to understand or feel what another person is experiencing from within their frame of reference, that is, the capacity to place oneself in another’s position *) )
Empathy is the ability and willingness to recognize, understand and relate to sensations, emotions, thoughts, motives and personality traits of another person
Unknown, but hits it very well
This personal ability to understand people, their motivation, sense their thinking, get an understanding of their needs is fundamental for any leader. Empathy is for me a form of appreciation of people. Leaders have this ability, some more developed, some less so. The degree to which it is developed is irrelevant, but it is important for individuals to recognize how much attention needs to be paid to empathy. Empathy is important in coaching situations to recognize how to support others and by what means. Empathy is also important for recognizing organizational shortcomings and being able to initiate appropriate countermeasures.
Listen to people – demand and encourage
An organization is able to attract great talent if – and only if – the overall interview process is a great experience and the players involved are fully motivated and willing (!) to attract new people. The interviewers need to fully stand behind the organization, the values and the culture. The organization can not attract people if that’s not the case.
As a leader one of your biggest duties is to work with your people. Apply the principle “Demand and Encourage“. As a leader you’ve hired great talent – and why shouldn’t you use the talent? Demand from people to fulfill their tasks, to reach goals, to outgrow themselves, to lead the company to success. Encourage them to go the extra miles needed to achieve personal growth. Listen to them, work with them – together – to master challenges ahead. Work together with them through the “LOVE, CHANGE, LEAVE” cycle.
Typically, people leave quite soon after they enter the “LEAVE” phase and it’s the leaders’ job to prevent people from entering the “LEAVE” phase. Another of my expectations on leaders is to give people reasons to stay, to support them, to encourage them to grow.
Does an experienced leader and a startup organisation go hand-in-hand? Or is there a nominated winner? I am in leadership roles since 2010 – quite some time. Early 2020 I had to decide if I wanted to join a startup – well, a young organisation. 10 years leadership experience and bigger teams vs. a young, well-funded, organisation with a great vision and roughly 15 people overall.
Just recently, end 2022, I reflected on the decision from almost 3 years ago. Was it a good decision to join a startup as experienced leader? Would I do the same again – enter a young organisation? Before I share my summary I’d like to share some of my impressions.
VUCA? I experienced it live and in color.
VUCA is an abbreviation and stands for volatile, uncertain, complex, ambitious. It is typically used as a description for the economic situation currently perceived in comparison to “the good old times”. Typically, VUCA comes as a very abstract und intangible description. I at least haven’t had the experience of a real VUCA environment – so far.
The young organisation changed this – a lot. The key paradigm of the overall organisation was and still is to get as much value for the company as possible in the finite amount of time left. This resulted in a series of constant changes in strategy and direction for the employees and the leaders (volatile ✅ uncertain ✅). As a lead person – in whatever department – it was always a tough decision between do it just “good-enough” or now is the “right” time to do it right (complex – ✅). Now, mix a bit of COVID with some financial crisis and the need to kick-off the next financing round. The end result are external signals that need constant interpretation and allow at best a “steer at sight” approach (ambitious ✅).
It takes a lot of patience, a “keep-calm”-mindset from an experienced leader in the startup to get the organisation ahead – in the right direction.
Time warp – 1 for 7
After some time in such a dynamic environment you start to realise that 1 month in the organisation feels like 7 months in real life. Decisions are taken so fast, projects need to be prioritised, organisational changes fly by, important meetings with investors and clients are lined up, technical escalation meetings and management meetings give each other a hand. It happens a lot in a minimum amount of time. So, better be prepared on how you organise yourself and the functions you’re responsible for. It’s definitely a different pace than what you’ve experienced so far.
Surprise? Surprise!
“Planning replaces coincidence by error.” by Albert Einstein. So true! Most of the other planning activities you do for roadmaps, budgets, mission, project planning, quarterly plans are typically altered after months, weeks or even days. After a while in this hamster wheel you realise that you can only prepare yourself for “not being surprised by any surprise” (borrowed with pride from D. Siegel and his great book “Decide & Conquer”). So, prepare yourself for the unthinkable – it’s likely to happen.
And out of the chaos a voice spoke to me: “Smile and be happy, it could be worse!”, and I smiled and was happy, and it came worse…!
unknown (most likely the “Chaos”)
There will be nobody to delegate to … get your hands dirty!
A lot of experienced leaders are used to have some people around them – subject matter experts eager to shine on topics. This is different in a small organisation. It’s you to shine – be prepared to get your hands dirty. I ended up – initially – installing notebooks, creating user accounts in Office 365, setting up the tech environment for performance ads, drafting a great recruiter strategy, put rough processes in place – which are better than nothing, but far away from good. No time to lean back. It hits you like a train.
Fun & lots of talented people around you
Typically, the people around you purposefully selected a young organisation. They are hungry for the pace, the responsibility, the growth and the purpose. The energy and willingness of these people is stunning. Clever, talented people around you – ready to grow. And they are typically looking for a certain level of experience to guide them, to indicate the “right” direction. That’s a part of the experienced leader – they’ll need your advice.
Experience matters, a lot.
You and your experience – you are the lighthouse in heavy water, you’re the rock in the surf. You have seen a lot in your career – so your prime action instruction when the organisation faces one of the aforementioned surprises: stay calm. Most likely you’ve been in comparable situations – others have not. Where your heartbeat parallels others in the organisation are close to panic’ing. In these situations all eyes are on you and typically it’s by applying simple management techniques and you get the situation cleared. The calmness is, however, important for the organisation. Your spot in the organisation is to support with your experience and bring it forward, fast.
Would I do this again?
Even the above mentioned points are surprises in its own and one might ask “Why would you even consider repeating such a journey?”. Well, “with great power comes great responsibility”. In no other environment you can move things as fast as in a young organisation. Impact, everywhere. Clever and eager people, everywhere. Surprises, well also everywhere. Fun, definitely. So, count me in for the next round!
Companies have core values, leaders should too – Personal core values. Many organisations spend a lot of time trying to figure out from their teams what is important to the organisation. What are the principles and norms that the team can relate to? These core values should give employees of the organisation guidance, stability.
Have you ever thought of doing such an exercise on your personal profile? Wait a minute, why would you do that? For me, it was quite simple. I needed to understand what is really important for me. What do I focus on in my daily leadership work? What values can people stand on? How can I become clearer as a person, as a leader?
I decided to share my personal core values so people can look them up and take me at my words. Like a user manual for me.
What’s important to me, Michael Maretzke?
The reflection and thinking phase – which took me some hours spent across a minimum of 3 months resulted in my core values.
For me, the personal core values are real values, no phrases.
These are People, Transparency, Simplicity and Performance – short: PSTP.
Personal Core Value #1 – People: What do they mean to me, Michael Maretzke?
People do their best. they grow. shine. make mistakes and learn. We are these people – we all have strengths and weaknesses. People – our employees – are the organisation. Every single person has individual characteristics, views, needs, fears, desires, motivations.
Most people are reflective enough to see a higher value for themselves and behind their work – the purpose. Some maximise wealth, others sell insurance, others optimise business processes. Everyone operates according to their own value system. Important for everybody is the “Why?” Why do I get up every day and go to work? People need purpose to deliver highest performance.
In addition to a sense of purpose, these people are driven by the opportunity to address problems and solve them alone or as part of a team. These head people feel comfortable when they can work in a self-determined manner – autonomy. Unlike on the assembly line, it’s not about optimising repetitive processes, but creativity and cleverness are required.
When these people pursue their work, they want to get better at the specialty they are pursuing. They want to master their field – mastery.
People and their leaders
The role of the leadership team is to enable a creative, creating organisation to do this. To this end, the leadership team ensures that everyone in the organisation understands what the organisation is striving for. Why are we doing all this? Once the direction is clearly understood, it is consistently corrected and communicated accordingly. OKR’s are a participatory model exactly for this purpose. Employees contribute their individual knowledge to the collective of the organisation. Through intelligent corporate goals, the leadership team ensures that the framework is set wide or narrow enough for the organisation to move in the desired direction.
Once the direction is clear, the leadership team ensures that staff have enough space to contribute. Mistakes are allowed and encouraged – only from mistakes will individuals and the organisation learn. Successes are confirmation, mistakes are learning opportunities. Through this freedom, staff take responsibility and relieve the leadership team. The leadership team can devote itself to other, more important topics. The experts work on the implementation and solution of the assigned tasks.
Person-centred and participative leadership models turn away from the Taylorist “command & control” model of leadership and focus on developing the employee – coaching. One – if not the – central task of the leader is to help the employee grow. Provide guidance at the right time, don’t intervene too early, avoid catastrophic consequences, but always stay on the edge of the comfort zone. Coaching enables optimal, individual development of the employee – towards readiness to take on bigger and more valuable tasks.
People who work in creative, formative organisations want to contribute, they want to be challenged and encouraged. Recognising this – and then implementing it successfully – is extremely important to me.
Without purpose – no buy-in from staff Without buy-in – no contribution Without contribution – no success.
Michael Maretzke
Personal Core Value #2 – Transparency: What does it mean to me, Michael Maretzke?
Transparency in communication is a key element in creating understanding. This understanding leads to wider acceptance of policies, rules, restrictions, strategies and other conditions that management needs to communicate to a wider audience. This knowledge, the background information, is an important prerequisite for an environment of trust. I argue that transparency leads to trust – and trust is, after all, one of the essential building blocks of an organisation.
Even in situations where the news is catastrophic for individual team members – for example, when the need to restructure the company leads to job losses – you should be transparent. Transparency in such cases gives people who remain in the organisation confidence in the leaders.
Be cautious! I am not saying that everyone needs 100% of all available information at all times. Of course, there are differences in the degree of transparency depending on the target group. But the information that is relevant to the target group must be communicated as early as possible.
Personal Core Value #3 – Simplicity: What does it mean to me, Michael Maretzke?
Simplicity affects both the structure of an organisation and the development of technical solutions.
An organisation must be simple in order to be understood. Only when employees understand their role and their tasks, when they know where their area of responsibility ends and where the area of others begins, can they give their best within the organisation. Simplicity enables them to understand their position within the organisation and the impact they can make.
Technical solutions tend to be over-thought and over-engineered. Take the simplest solution to your problem, forget the gold rim solutions. When working in a team on possible solutions to complex or complicated problems, I think it is always advantageous to choose the simplest solution with the least necessary complexity. The focus is on solving acute problems, not anticipating future problems. If you aim for the smartest – and most likely more complex – solution possible, you invest now in not-yet-known problems of the future. You may solve the problem, but you may not. Point taken: simple solutions will probably need revision or perhaps even replacement in the long run, but you still gain time acutely. You solve the problems of the future when they are known and actually occur.
Personal Core Value #4 – Performance: What does it mean to me, Michael Maretzke?
Performance here means: Impact on the organisation and technology.
Normally, an organisation acts in an economically oriented way and strives for profit. The outcome of an organisation depends on the willingness of people to go to their limits – and beyond. Outstanding organisational results require a high level of commitment from people. They drive the organisation to perform at its best. They want to give their best to achieve the best for the organisation. Results, as quickly as possible. Striving for success. A good way to drive an organisation to peak performance is to implement OKRs well.
In technology, performance means optimising a system to produce customer value as quickly as possible. A high-performing system delivers web pages to the user as quickly as possible, it also delivers finished developed functions to the user as quickly as possible using continuous integration or continuous delivery, it also uses methods and tools to help developers write high quality code in the shortest possible time.
In both cases, organisation and technology, it is all about the right mindset. Strive for performance to get as much real value or result as possible from the system.
Coincidentally, I stumbled over the book “DECIDE & CONQUER” by David Siegel. I was attracted by the fact that the CEO of meetup.com would report on his experience as being the CEO of a very community focused organisation in a heavy change situation. David got me because he describes his bumpy ride during various transition phases (onboarding, changing vision / strategy, being sold and eventually COVID). And even better – he summarises his key learnings in 44 challenges directly reflecting from these situations – and describing en detail how he decided and why so.
The book is a great read for people who want to understand the mindset of a CEO. The CEO, who some people see as god-like in their own organisation, is a real human being – in this case David Siegel. The whole book is easy to read, brings back many memories, and gives a lot of advice on how to make decisions in similar situations. Sometimes while reading a paragraph I had to pause and let the words sink in. David really makes you think and reflect on the situation described. If you are in a leadership position, there is a good chance that you have experienced this situation as well. Usually David gives a completely different perspective on what you would have done in similar situations. He makes you think. The “ground rules” – David’s personal decision-making framework – are impressive. He introduces these 11 principles at the very beginning of the book. And he refers to them constantly. The entire book is divided into 44 challenges. The challenges are essentially on a timeline that describes David’s journey to becoming CEO of meetup.com, to onboarding, and to various other situations. Some of the challenges may not be 100% relevant (have you ever had to sell your business?), but still David shows a new perspective in each situation. This different thinking, the change in perspective, is also valuable for other people in leadership positions. I would really recommend this book to anyone who wants to expand their decision-making capabilities in different situations. It’s a great read – a mix of learning and entertainment.
The ground rules – David’s personal decision framework
Right in the beginning of his book, David names his ground rules – his personal decision framework. He uses these principles during the whole book and reminds the reader on what principle he wanted to emphasise with the just described situation / behaviour. I wanted to bring the principles up here again and give an example that describes what David had in mind with the principle. They show up during the entire book and a lot more examples are given.
Be kind
David talks about situations where he needed to lay-off people. He suggested to name the lay-off “lay-off” and adapt the whole procedure to the company culture and communicate the whole process transparently (be kind to your employees). Same applies if people don’t longer fit the company expectation – show them a kind way out of the organisation. Also, in situations where people need your help or access to your personal network – be kind and support them.
Be confident
David describes himself as a very people oriented person with a strong willingness to empower people. Therefore, the following cite is good to remember if you’re also a people focused person:
You’re not paid to manage by democracy. You’re paid to decide.
David talks about huge numbers of people leaving the company and asks what to do when this happens. Very good advice from him: Let them go and start rebuilding. In your communication in public be honest about so many leaving,
Be bold
As a leader you need to act. Especially in crisis – they present a huge opportunity for change: be confident, be bold.
If in wartime mode – be bold and enforce significant change if needed to change for the better.
Expand your options
The “expand your options” principle was a special one. I’ve never thought about actions you naturally wouldn’t do from that perspective. If looking with that angle on e.g. “smart talk at a party” or “reaching out to hundreds of contacts to get the one job” the activity becomes really meaningful. It supports you to expand your options now – or in future.
David recommends to hire team members – especially executives – via the personal network instead of limiting it to the options presented by head hunters. He really has a point here – but you better have a vivid personal network.
Also, the hint “if empowering is not working, it’s time to micromanage” made me think. My nature is to believe in the power of self-organising teams and to empower people. So is David’s. However, he has a passage in the book where he clearly identified the limitations of the empowering approach. He changed his leadership style towards commanding to expand his options.
Be long-term focused
In cases where you need to prioritise activities or projects, always try to focus on the long-term impact. Short-term decisions usually result in quick changes in direction, activism. Long-term brings in stability. Same applies for your investors. If being able to select your investors – select them according to their long-term goals.
And – back to networking – in networking there is no “bad” conversation, you never know.
Be honest
Honesty is a big influence in the book, in David being a CEO. He suggests to be honest in the relation with your investors, in negotiations and especially in employee communication. If you have to announce a lay-off, name it “lay-off” – a lay-off is a lay-off is a lay-off. Give people details about news – bad or good ones. The trust in your communication style will support them to better understand the news.
Be speedy
David gives multiple examples where speed actually really matters – especially in communication. If bad news need to be announced (e.g. the company is being sold) – do it as quickly as possible – don’t wait. Waiting means news will find its way through different channels resulting in irritation and eroding trust in you as a leader. This is especially critical if a press-announcement is on its way – you need to be faster than the press. People deserve to get the information first hand from a trusted source.
During onboarding, build your executive team as quick as possible. Don’t waste time on endless interviews looking for the perfect candidate. There will always be pros and cons with people.
Also, when announcing your new strategy for the company – better to have a half-baked strategy in place than nothing to give guidance for people. If new learnings appear, correct and adapt the vision and strategy on the way.
Be pragmatic
David also talks about dogmatic vs. pragmatic decisions. When meetup actually got at risk with the COVID pandemic he needed to be very pragmatic. He purposefully decided to break with the years-old conviction that meetup was all about in-person events.
“I needed to make a decision on my own and I needed to be pragmatic. I decided that we needed to embrace online events.”
Do what’s right for the business
That was an interesting pillar for me as well. David had multiple examples where I needed to think twice until I got the point. “Remove parts of the business if it helps saving the remainder part” or “if needed, prioritise company success over employee morale” sounded logical right from the beginning.
More interesting was “do what’s right for you, but make sure you also do what’s right for the business”. Don’t loose your personal interest – combine your personal well-being with the company well-being.
Work for your employees
When meetup experienced people leaving the organisation in masses, they started to work for the employees. They focused on positive experiences (e.g. parties on positive reasons – instead of exit parties, started community lunches, summer BBQs, …) and offered critical employees retention bonuses during this critical period. Slowly, they were able to keep critical people and turned around the ship.
With the new meetup organisation he focused on processes and systems to support the team’s decisions, enable creative approaches and reward extraordinary performance
Be surprised only about being surprised
This was the most outstanding one – and in parallel a really valuable hint. Expect all and nothing. David described many really strange situations with his investors and owners. And not being surprised by the fact but still be able to work them is really a great advice. Two examples he gave are volatile leaders where you need to expect everything, every minute and COVID.
Some aspects to keep in mind from “DECIDE & CONQUER” by David Siegel
In the beginning of his book, David describes his “ground rules” – a set of principles he’s rooting his decisions on. They support him to define his interpretation of the role of the CEO. I’ve listed the ground rules below and give some examples to make it more memorisable (at least for me).
A great example in his book is on good vs. bad leaders is this:
“A good CEO realizes that their job is to hire the right people and build an organization’s capability to make smart decisions. A bad CEO often doesn’t realize how little influence they should have on certain decisions and pushes forward, only to micromanage, disenable, and ultimately force the exit of good people, whose responsibility it should have been to make those decisions. In other words, a good CEO delegates power and works for their employees, while a bad one clings to power and makes their employees work for them.”
Another one on the importance of financing:
“When it comes to finances, one must be pragmatic, when it comes to priorities, one must be long-term focused.”
Being in interview situations yourself:
“Interviewing is dating – don’t marry your first date, and if there are red flags during the dating process, those red flags will only become stronger during marriage.”
If you left your job with a specific reason:
“Be retrospective after leaving a job. If you left for specific reasons, make sure you don’t go back to the same problematic situation”
Don’t forget if thinking about big numbers, hard conditions, and unthinkable demands:
“You are always negotiating and everything is negotiable.”
Not to forget when you start into your new role as CxO:
Build trust from day 0
Communication and transparency are king and queen
Don’t be afraid of bad hires – don’t expand the hiring process endlessly
Write the strategy of the company as a future press release
If you have to cut down costs – and impact the organisation – do it deep and act quickly and transparent – make cuts needed to set you up for long-term success
Hiring your executiveteam:
Hiring leaders is a CEO job
Hire for complementary skill sets
Executive Hiring with the four-step framework (page 85)
Never ask for references, do background research
Working with your investors or your superior:
Volatile leaders – swinging their opinion to A the one day, to B the other day – avoid them
Working with board – don’t ever trust any direction that lacks financioal accountability and solely prioritizes short-term imperatives.
Creating an impact on culture as a CxO – what you should focus on / emphasise:
10) EQ is more important than IQ
9) Transparency
8) Focus
7) Revenue
6) Performance-driven culture
5) Accountability
4) Diverse and inclusive culture
3) Analytics wins
2) Learning
1) Support and push team
If being acquired, keep your company stand-alone – don’t adopt the buyers culture
OKRs – uncovered. An Overview on Objectives & Key Results.
Objectives and Key Results are widely discussed – but what are they? Why are they so important? What do you need to keep in mind when thinking about them? How do they fit into any organization? What are prerequisites to implementing them?
This blog entry and a presentation on slideshare about OKR’s – uncovered answers some of these common questions on OKR’s.
OKR’s push us far beyond our comfort zones. They lead us to achievements on the border between abilities and dreams.
John Doerr, “Measure What Matters”
A brief history of OKR’s
The list below shows some milestones to remember when it comes to management methods.
1900 – Taylorism – people are no human beings but merely resources. They need to be told what to do. No motivational aspects. Others control the entire work. No self-control.
1950 – Management by Objectives (MbO) recognizes people as individuals. Motivation on an individual level starts playing a role. Birth hour of transactional leadership – principle of give and take. Achieving goals leads to earning rewards.
1970 – OKR at Intel – CEO Andy Grove discovered a mismatch between the management model MbO and the reality of a high dynamic in the surrounding world. He started with the visualization of Key Results as milestones. It became visible how goals could be reached. People’s empowerment increases and as a result their commitment.
1995 – OKR 2.0 at Google – Today’s OKR method is a variant of the original Intel version brought to Google through John Doerr. He got to know the method when working with Andy Grove at Intel. The decrease of cycle time and an increased level of agility made the OKR 2.0 version a perfect fit for the digital age. Google adopted the OKR method for a simple reason: Googler’s at these early days were data addicts. They simply liked the fact that progress towards an objective got measurable – quantify instead of quality-only.
Now – New Work – The OKR model supports aspects of the new work model. Each and every person strives for purpose and want their share of work being reflected in the overarching organization’s vision and purpose. OKR supports with the transparency aspect. OKR and management 3.0 fit together as well. Also the communication, transparency and streamlining aspect by OKR’s is well received by management 3.0.
Characteristics of OKR’s
“Objectives and Key Results” – OKR – is a framework to set and align goals and measure achievements. The Objective is ambitious and needs to feel uncomfortable. The Objective is clearly non-measurable and qualitative by nature. If the Objective doesn’t make you feel uncomfortable it’s too small and not a good Objective. The Key Results clearly make the objective achievable – they draft a path to reaching the Objective. The Key Results are measurable – need to be quantifiable. They lead to grading an Objective.
OKR’s is a great communication tool. Due to the bidirectional process starting at the top and receiving feedback from the organization produces maximum transparency. Agreeing on the most important topics to work on during the next period of e.g. a quarter keeps the whole organization in sync and focused. The importance of the objectives is clear to everybody within the organization – everybody and always. Besides the focus, synchronization and transparency, OKR’s make the whole progress towards the objective measurable – quantify, not qualify.
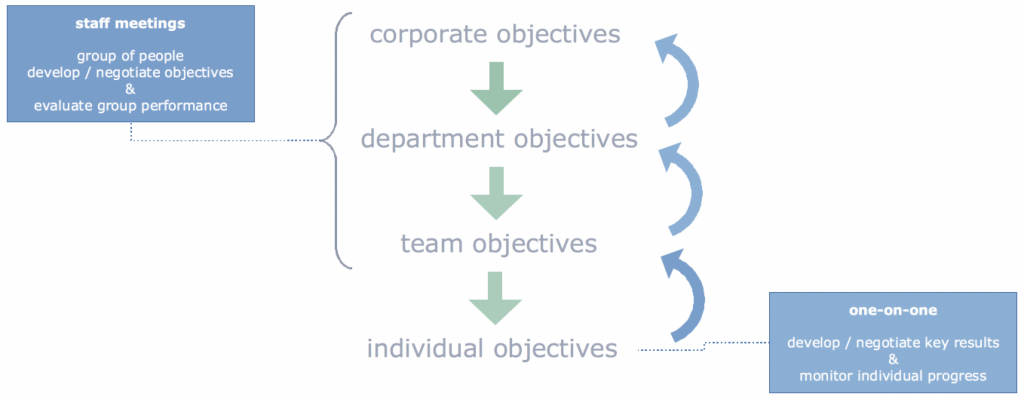
The process around OKR’s
The process around OKR’s – discussed and agreed between management and individuals
The overall process to establish OKR’s seems like an heavy invest of people’s time at a first glance. Staff meetings with C-Level, head-of’s with team-leads, team-leads with teams and back again are an investment. However, the whole organization gains transparency, commitment and focus. Doesn’t look like a bad trade …
The staff meetings are public where Objectives are described by management and discussed with people. The Objectives dribble down the organization in a series of other meetings. Results surface towards management – finally all Objectives need to be agreed upon by staff and management – no dictating. Typically 60% of the Objectives come from bottom-up and 40% from management.
The individual Objectives are defined by the individuals and discussed with the line manager. It’s the employee defining the personal Objectives – ensuring commitment and understanding the value brought in to achieve the overarching Objectives.
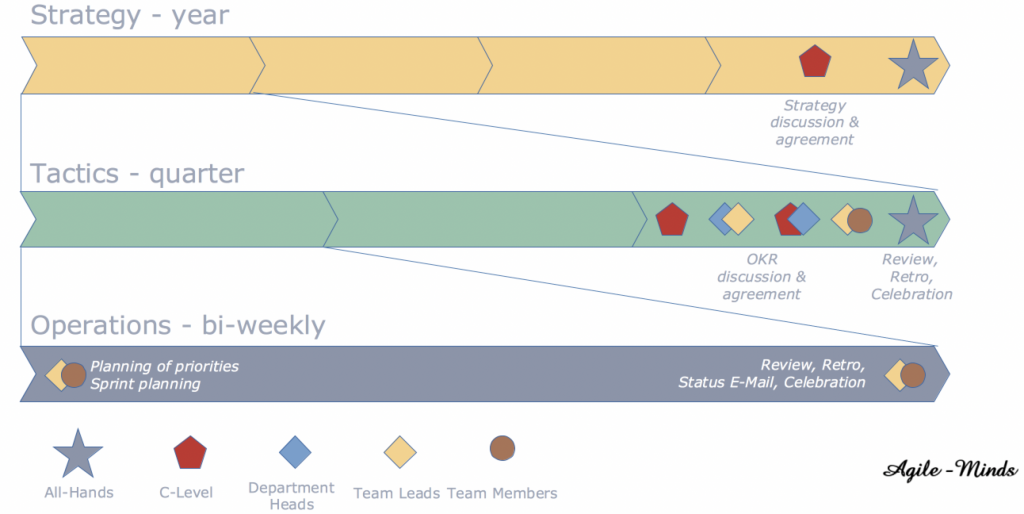
OKR’s cadence – who? what? when?
Strategy – yearly
C-Level revisits the company strategy at least once a year and reports corrections and refinements back to the staff in an All-Hands meeting.
Tactics – quarterly
Short before a OKR period ends – typically a quarter – various combinations of management discusses and finally agrees on the next periods’ OKR’s. The combinations ensure free flow of information, results, concerns, objectives from top to bottom and vice versa. In an All-Hands meeting at the end of the period the achievements are reflected, graded and – most important – celebrated. A retrospective uncovers process flaws and potential improvements to be addressed in the next period. The All-Hands is also the place to communicate the OKR’s of the next period.
Operations – bi-weekly
The operation of the OKR process fully integrates with existing agile methods (e.g. SCRUM or Kanban). The agile review, retro and celebration is topped-up with further information about Key Results and where the organization stands reaching the Objectives.
Basics around OKR’s
Agree on 2-3 Objectives to focus the respective organizational unit – no more than 5 Objectives. Agree on 3-4 Key Results per Objective – take care to have them measurable with KPI’s and a numerical expectation. Keep the ratio 40% : 60% – 40% of the Objectives come from the management and – more important – 60% come from the basis. This ratio ensures high commitment and engagement amongst the involved individuals. All involved participants have to mutually agree on the Objectives, there is no dictating from management.
From a scoring and grading perspective aim for 60%-70% achievement per Key Result – this is an excellent value. Not too ambitious, but definitely a long stretch. 40% and less? Or 100%? Both are bad scorings. 40% or less indicates either the OKR was too ambitious, non-realistic or there was definitely a huge problem within the team. 100% means the OKR was not a stretch at all – more like a low hanging fruit.
The OKR’s are set quarterly and annually – but not set in stone. If conditions force a deviation from Objectives the team is free to decide to change the Objective – again with all participants’ agreement. Grading of Objectives happens every quarter. The OKR’s are defined at the company level, department and team level and also on an individual basis. The Objectives and Key Results are publicly available for the entire organization – all OKR’s, the individual’s included.
Ah, and finally. To keep the OKR’s effective and credible, to keep all people involved motivated and encouraged to deliver top performance, NEVER connect the OKR process with whatever employee performance process you might have in place – NEVER! Also, don’t associate OKR’s with money – get rid of the variable payment portion! If not possible to return to a 100% fix salary – don’t put money behind the OKR’s.
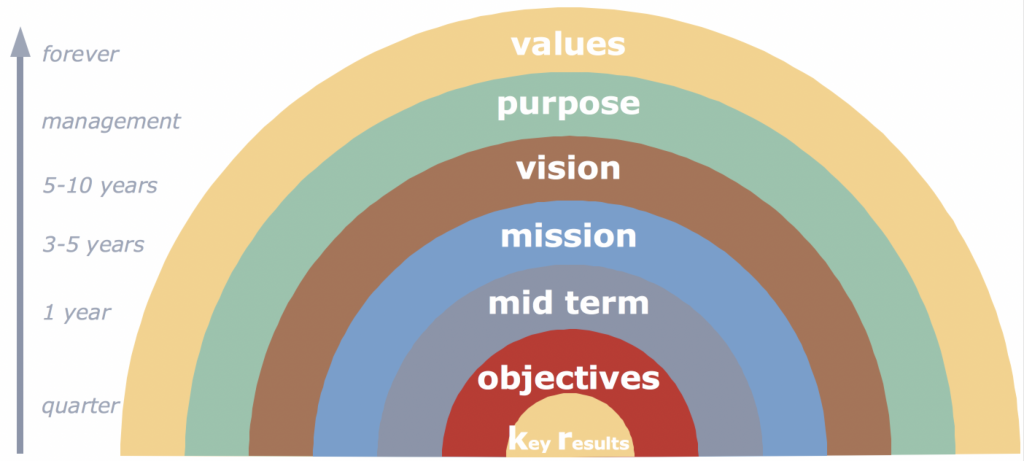
OKR’s and company values, purpose, vision and mission in context
OKR’s, mission, vision, purpose and values in perspective – Where do OKR’s live?
A company producing value for customers strongly aligns in some ways. The organization defines their core values during founding. The values don’t change typically – they define the company and established by the founders. The purpose of the organization aligns strongly with the values and adapts with the management in place. A change in management means usually also a change in the purpose of the organization. The company vision holds for 5-10 years, the mission 3-5 years and the mid-term goals for around one year. The OKR’s account for roughly a quarter and align with the overarching strategic goals.
Scoring and grading of OKR’s
Each KR is graded individually and the average of the KR’s indicate the overall Objectives grading. There is no fancy weighing or calculation involved – every KR has the same weight and it’s simply the average. The sole purpose of the grade is to reflect the progress towards the overarching Objective. The goal is to reach 60% to 70% accomplishment for the Objective – reflecting the nature of a stretch Objective, but still being reachable. Receives an Objective low grades, the owner need to reassess the reasons for the low grades. What do we need to do differently to achieve the Objective? Is the Objective still valid? Still worth doing?
Grading on all levels reinforces the commitment on all levels towards the bigger company Objective. Each Objective owner scores the KR’s and hence the Objectives and makes the grades public – again on all levels. The OKR owners of non-individual OKR’s explain the achieved grades and potential adjustments for next quarter. The CEO grades the whole company and explains it publicly – as all OKR owners on team and department level.
OKR examples
Example for Personal OKR with grading (Objective’s grade = average of KR’s grading)Example for Team Level OKR with grading (Objective’s grade = average of KR’s grading)Example for Company Level OKR with grading (Objective’s grade = average of KR’s grading)
Prerequisites for OKR’s in an organization
OKR’s sound just too good to be true, right? But they’re just a piece in a bigger jigsaw puzzle of methods. OKR’s are dangerous in a way that they can really hurt an organization if introduced wrong or at the wrong time.
Wrong introduction? Bring in some experts who have introduced OKR’s into organizations. Learn from their experience, let them support you in getting your organization behind you and your ambition to change the goal setting framework.
Wrong timing? “It’s never too late or too early.” Well, OKR’s live well in a culture with already implemented – or embraced – principles of agile management (think small teams, think network structures, think customer centricity). If your organization is still living in yearly performance reviews, hierarchical organizations, political games and strict command-and-control structures – DON’T implement OKR’s – it will very likely hurt more than it helps. Your organization must be ready to embrace, to enjoy, OKR’s.
Don’t crash your organization.
Marty Cagan, SVPG
Setting OKR’s surfaces organizational problems – deal with them
Ken Norton, Google
OKRs aren’t going to compensate for your culture.
Ken Norton, Google
Don’t link financial compensation to OKRs – NEVER.
Marty Cagan, SVPG
Other resources on OKR’s
Google and OKR’s
Video about the original way of working with OKR’s at google – presented by RickKlau (2013) with Google Ventureshttps://youtu.be/mJB83EZtAjc
I know Luis Goncalvez since quite some days and I was surprised when he gave me a copy of his book. I read his book “Organisational Mastery” on organisation transformation within a week and was really impressed. The book is split in two parts – the first part setting the scene with some theoretical background and the second part where the theory gets practical. The second part is a great mix of Luis experience in building organisations and real hands-on practical tips on how to do what in which sequence. The book is not meant to be a step-by-step guide for each and every organisation – but there are some patterns included, some practical tips which might support you in finding the right way to changing your organisation.
In “Organisational Mastery”, Luis bases the whole transformation – which sometimes appear to be quite radical – on five key elements:
1. Translating Strategy Into Daily Operations
Luis explains how OKR’s and / or Agile Portfolio Management are a key element in connecting Strategies and daily work, giving meaning to the small daily tasks and connecting them with the broader picture of a strategy aiming to reach an even bigger vision. Furthermore, he talks about the relevance of CoD (Cost of Delay) and how the understanding of this KPI can help in prioritization of activities. He also talks about the difference for an organisation if working on products or on projects. He also highlights how the goals and the strategy are aligned in a certain cadence.
Luis raises some criticism on typical hierarchies, no matter if line or matrix organisation. He’s a big proponent of mini startups within traditional organisations. No bi-modal thinking and working. Just create self-contained and independent mini startups around your key products to minimize dependencies as far as possible. Prerequisites for such an organisation is clarity on vision and the will to say “no” to non-relevant activities.
3. Continuous Improvement
Luis introduces the Organisational Impediment Board as a tool that allows the identification of issues, problems, in-efficiencies, … on a broad level with attention from all levels of people – including C-Level management.
Luis positions the Communites of Practice (CoP) as a key element for knowledge sharing within an organisation of any size. These communities exist on all levels: team, product, organisational and external communities. An example for external communities are meetup and tech talks organised by the company for the community with the aim of getting new knowledge and talent attracted to the organisation.
5. Driving innovation
Innovation needs to be driven purposefully. Luis proposes the frequent execution of Design Sprints (Design Thinking, Google Sprints).
The whole book explains the five pillars and the effect on the organisation on a theoretical and practical level. Personally, I find the book very inspiring and hope to get some of the mentioned aspects implemented in an organization quite soon.
The book “the REMIX” by Lindsey Pollak deals with challenges and solutions in a multi-generational workspace. Me, being a Generation-Xer, working with a lot of Gen-Y and Millenials, read the book and had some real A-HA moments. Those moments make a book valuable (and allow a better understanding of your employees, colleagues and even kids). The book is definitely worth reading. It is a good mixture of theoretical aspects and practice tips, examples and easy to read (especially for a non-native). Most impressive – for me – were the rules for remixers – people who pay special attention to the differences in expectations due to different ages / generations. I’d definitely recommend the book to “new work” addicts and leaders with a “lean” or “agile” mindset.
Lindsey’s rules for remixers – something to keep in mind from “the REMIX” by Lindsey Pollak
#1 Stop the Generational Shaming.
“I see no hope for the future of our people if they are dependent on the frivolous youth of today.”
poet Hesiod, eighth century B.C.
There is no point in blaming other generations for whatever they do. Most likely it’s a form of socialization, a habit – and most likely it’s up to us to try to understand them better.
#2 Empathize.
Replace the blaming from #1 with empathy. Try to understand them. Why does this person of another generation act like she / he does? What’s the motivation behind? Try to see the world through the person of the other generation.
#3 Assume the Best Intentions.
Expanding on #2 Empathize, always assume the best intentions. This enables you to better understand the “why” behind somebody’s behavior. It also allows to explain the “why” behind your reasoning.
“It’s so annoying that the Millennials and Gen Zs on my team always wear earbuds in their ears at work.”
#4 Think “And”, Not “Or”.
If you ever come across to make a decision “the old way” or doing something “the new way” – never make this exclusive choice – combine the best of both.
#5 Remember That “Common Sense Is Not So Common”.
Don’t take your socialization as granted. Other people were raised in different economic conditions and in a different technology context.
Executive: But that was confidential! Millenial: You never told us that! Executive: I didn’t think I had to!
Traditionalists, Baby Boomers and Gen Xers have a different understanding of sharing information. For Millenials and younger information sharing is a natural habit and leads sometimes to misunderstandings.
#6 Don’t Change What Works.
Do not change what works in your leadership style and habits. Good leadership skills are inter-generational and independent of the age of people you’re working with.
#7 Be More Transparent.
Share information with your people, explain rationales behind decisions – make them understand to raise their understanding. Don’t be 100% transparent – but more transparent.
#8 It’s Okay if Everybody Wins.
Give more trophies for accomplishment. Celebrate, everybody wants to win, wants to be a hero. Don’t allow questions like “When there’s an intergenerational conflict, which generation should win?” – the right question would be: “How do we flex and adapt to one another so each person can have the opportunity to be part of the winning team?”
self-expressive, group oriented, purpose-driven, tech dependent
Generation Z
1977-tbd
tbd
cautious, technology advanced, diverse
To keep in mind from “the REMIX” by Lindsey Pollak
Lindsay cites an CMO’s answer on a panel discussion on the question “If you could go back to the very beginning of your career and give yourself one piece of advice, what would you tell your younger self? What do you most wish you had done then, knowing what you know now?” The CMO said: “If I could go back to the beginning of my career and give myself one piece of advice, I would tell myself not to be so afraid. When I think back on my career – and I have been very successful and achieved a lot – but to this day I still think about and regret the jobs I didn’t apply for, the raises and promotions I didn’t ask for, the ideas I had and didn’t share. I don’t regret my mistakes or embarrassments of failures; what I regret are the times I held myself back.”
We use cookies to optimize our website and our service.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.